Title here
Summary here
September 4, 2013 in Systems5 minutes
Wow. Lots of talk regarding overlay networking, both last week, and now this week. No doubt largely caused by the VMware NSX announcement last week. This post is an attempt on my part to clarify some fundamental ideas regarding overlay networking for my own benefit, but hopefully it helps you too. After all, we’re all learning.
I’ll also be referring a LOT to some community content from blogs and twitter, because there’s a lot of great opinions out there. Folks, if you’re not part of this conversation yet, push and shove your way in because this is where the cool stuff is happening right now.
The problem is clear - when it comes to networking, change - the kind of change that you experience in an environment like what I just mentioned - is really hard. We still power our networks with teams of net admins with console cables, (yeah, I know puTTY exists) running around and satisfying MAC requests when a customer gets signed up, or a new security policy is implemented. And don’t forget the political issues - many organizations are still very siloed, and if communication does exist between the server and network teams, it’s usually pretty bad, and sometimes even hostile. (Don’t believe me? Try working for a VAR.)
Another big problem in networking is that we’re starting to trend towards expensive, elaborate solutions in lieu of simpler solutions that would end up working better. Remember, KISS (Keep It Simple Stupid). Generally speaking, we have preferred to implement relatively elaborate technologies to get around our problems, most notably in the data center, ever since the massive adoption of virtualization technology. What we’ve learned is that while VLANs are and were a very useful tool, they’re not as scalable as we need them to be, and they are a very volatile network artifact.
If I could quickly summarize the “why” behind overlay networking (and this is hyper simplified) I would state it twofold:
It gives you more flexibility, allowing you to be agnostic of the underlying network fabric (known throughout this post as the “underlay”). Your network topology is defined by virtual interfaces on each network device or hypervisor, and is identified through tagging mechanisms (i.e. VXLAN) or through down-and-dirty L2-L7 categorization, using a variety of tools, most of which haven’t hit the market yet. The point is that there’s a lot of potential here because we’re no longer tied to a hardware platform
The “underlay” becomes more simple. Since we’re classifying traffic into overlays, the “underlay” need only be an IP network. This means that we now have the option of running an entire Layer 3 datacenter - something we’ve not really had the chance to do in this way before. Most arguments against doing this are pure FUD. This is nothing new, guys. It’s IP.
The Packet Pushers were the star of a recent episode by Engineers Unplugged over at Cisco and it’s worth a look - a vendor agnostic overview of overlay networking and some of the things you can do with it, but more specifically the impact on what we’re coming to know as the “underlay”.
So now, a specific look at each area.
The key behind the overlay is to identify virtual networks using some kind of tagging mechanism. If we’re talking about something like vXLAN, this is not really a tunnel (just like 802.1q tagging wasn’t really a tunnel). It’s merely a header to stick in between the “overlay” traffic, and the “underlay” traffic.
This allows us to form a “virtual wire” between two hypervisors, giving us our virtual network, overlaying the physical topology.
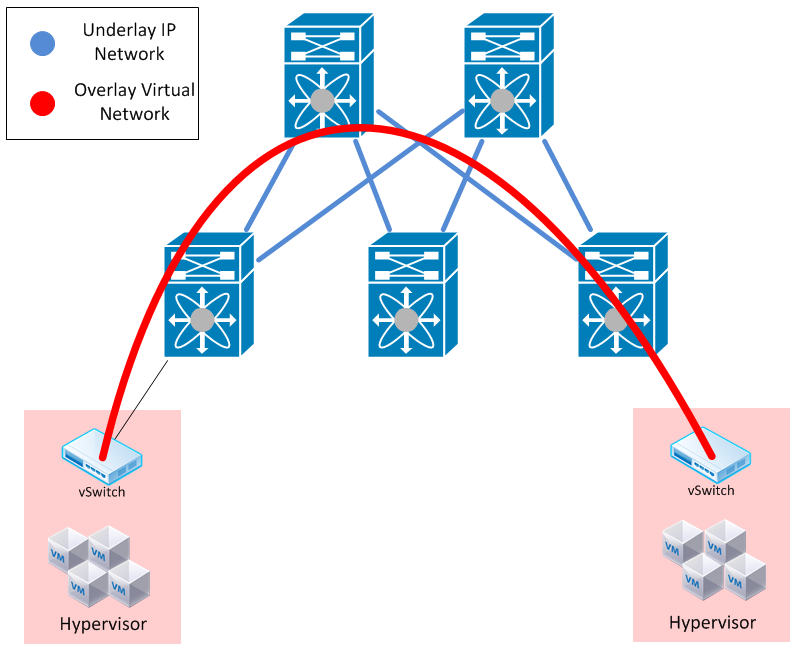
Ultimately, the overlay itself is a fairly simple concept. The majority of the marketing material that’s come out regarding overlay products like NSX are an artifact of the SDN controller. The overlay itself is merely a form of classifying traffic that is considered to be a “member” of one of these networks set u.
The vSwitch’s primary responsibility is to be aware of these virtual networks, and classify them according to the mechanism in place. Could be vXLAN, could be NVGRE. It could also be OpenFlow installing specific flow entries for each application, and categorizing each flow entry into a “virtual network” configured via ovsdb-proto. Either way, this is still the vSwitch we used, but also has the additional responsibility of being aware and taking part in the virtual networks.
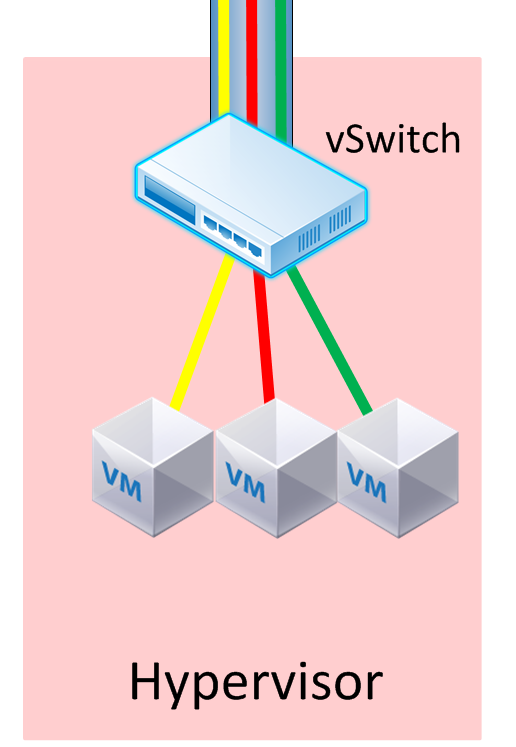
The vSwitch can also perform some higher-level forwarding decisions. For instance, when we have to forward traffic between subnets, we have to send the traffic northbound to a router or L3 switch, then it comes right back down into the virtual environment. This is router-on-a-stick, by every definition. You know, the basic inter-VLAN routing example in CCNA class.
So…..instead of fowarding to a northbound router, then hairpinning back, we can route the traffic within the vSwitch. We’ve saved that traffic a costly trip up to the network core. We can even incorporate L4 decisions here as well if needed, providing more specific forwarding decisions, as well as some basic security.
Virtual appliances like Vyatta or CSR 1000v are still very relevant in this model.
Distributing stateful functions like NAT or load-balancing can be extremely tricky. As a result, it’s nice to have that central point in the virtual environment where global policies are enforced. The better the integration between the SDN controller handling the overlays and these appliances, the more seamless the experience.
This post is continued in Part 2.