Title here
Summary here
August 29, 2012 in Systems5 minutes
I know vXLAN has been around for a year now, but because of the reviews it got from the community immediately upon announcement, I decided to let it mature as an idea before I got involved. Here are some of my thoughts after attending a vXLAN session by Cisco at VMworld 2012.
vXLAN really just solves one problem. Most virtual infrastructures depend on L2 connectivity. vMotion is a good example of this. However, building out a pure L2 infrastructure has its limitations. Eventually, you’re going to get so big that you either run out of VLANs, or other constraints get in the way. vXLAN gets around the limitation of a pure-L2 design by encapsulating frames into IP/UDP so that you can extend into other L3 domains. This seems to be aimed primarily at cloud providers but could find a home elsewhere as time goes on.
vXLAN uses IP Multicast to get traffic to where it needs to go. This means that after the VM traffic is encapsulated in IP/UDP, this packet uses multicast to get delivered to the hosts running the same multicast group, and thus, the same vXLAN ID. You can also share a single multicast group with multiple vXLANs, so you’re not limited by the number of multicast groups. I actually like all of this because multicast is where a feature like this belongs, but it requires a high level of networking effort. This is why integration between the server guys and network guys is so key - can’t just go tell the network guys to turn on multicast. This has to be a solution both teams arrive at together.
Now….if you want route between vXLANs, you do have a few options. It could be said that the vXLAN to VLAN gateway could be used to get all frames to a routing device, but that’s pretty much just router-on-a-stick all over again. A better option is the ASA 1000v, which is the firewall version of the product, or the CSR 1000v, which is just a router. The former is out now, and the latter is currently in beta.
You might be saying that I’m a fan of vXLAN. My answer is that I’m nothing until I can set it up myself. However, I have one beef with Cisco on this.
vXLAN running on the 1000v requires that the device routing traffic out of VLAN used for encapsulating vXLAN be configured to support Proxy ARP. (shudder)
I asked about this. Cisco is saying that this is a limitation of the ability for individual vmkernel ports to have their own default routes. If ESXi was able to have their own default routes per vmkernel interface, this wouldn’t be necessary, because you could set your own gateway to send the encapsulated traffic to.
This does not have anything to do with the default gateway of the VM itself, this is post-encapsulation.
However, this means that the 1000v is pulling the default gateway from ESXi. It’s understandable that we’re limited by the ESXi routing table, but in my opinion, they need to define it somewhere in the 1000v to override this function and maintain a separate default gateway for encapsulated traffic. In my experience, proxy ARP is bad, and it should be avoided.
From the Cisco 1000v vXLAN Implementation Guide:
VXLAN VMkernel interface IP address is used to encapsulate and transport VXLAN frames in a UDP tunnel. The VMware host routing table is ignored. The VMKNIC’s netmask is also ignored. The VEM will initiate an ARP for all remote VEM IP addresses, regardless of whether they are on the same subnet or not. If they are across a Layer 3 switch or router, you need to enable the Proxy ARP feature on the Layer 3 gateway so that it can respond to off-subnet ARPs.
Yes, they’re essentially describing the function of Proxy ARP, and it makes sense if you’re bound to the routing table of the host. My question is - why is that the case? If you’re bound by the routing table of the host, it makes a whole lot of sense to abandon that model and maintain separate routing for post-encapsulation traffic. That’s the entire reason for using VRF, so that you can maintain different routing tables for different use-cases. Yes, VMware could implement something like VRF (and they should), but if this is a limiting factor, don’t rely on a vastly insecure model like Proxy ARP to get around this.
Another thing the speaker went over is OTV. This is used to extend the Layer 2 functionality across datacenters so that things like vMotion would work natively. Sorta kinda works like MPLS, but obviously the architecture is different and the two are aimed at solving two different problems.
Then, he whipped this out:
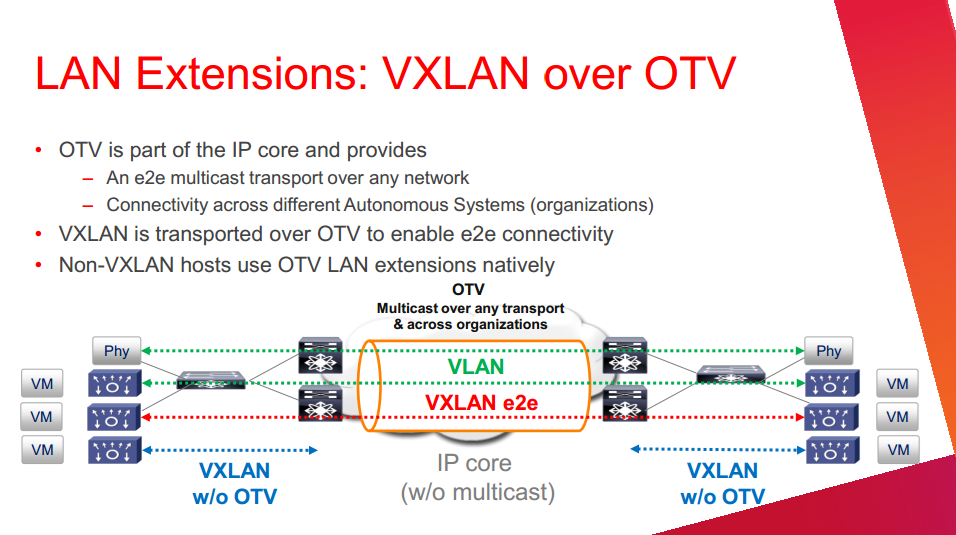 From Cisco
From Cisco
He did not go into a ton of detail on this, but from what I gathered, the point in running vXLAN over OTV would be to enable that end-to-end, or datacenter-to-datacenter connectivity. I was skeptical at first, but I took a step back and realized this was just simply another way of getting the two ends to talk. If you want to set up OTV between your datacenters, vXLAN can ride on top of it.
Candidly, I’d probably be more interested in simply running over MPLS, which is much more common and haven’t heard ideas to the contrary. In many cases, datacenter connectivity is private line, high bandwidth, so it seems to make more sense to rely on just routed multicast on the wire, rather than encapsulate within yet another layer.
I’ll be the first to admit that I don’t have a ton of experience with this stuff, but from where I sit, these are my areas of concern. vXLAN is a nice feature to have, especially if you’re a cloud provider, but in my opinion there are still a lot of unanswered questions and a lot of wrinkles to iron out.
Cisco has put together a nice page on everything 1000v, you can find vXLAN stuff and much more here: https://communities.cisco.com/docs/DOC-24984